KQL self-join pattern
In my day job, I spend a lot of time querying and analysing vast amounts of security data in Azure Data Explorer (ADX)/Kusto to find interesting patterns and prototype detections.
A common KQL pattern that I find particularly useful is the self-join - where a cached, pre-filtered table is joined back to itself to further filter.
Taxi Example
For this example, we’ll re-use the Seaborn Taxis.csv sample dataset (loaded with externaldata).
let TaxiData = externaldata(
Pickup:datetime,
Dropoff:datetime,
Passengers:int,
Distance:real,
Fare:real,
Tip:real,
Tolls:real,
Total:real,
Color:string,
Payment:string,
PickupZone:string,
DropoffZone:string,
PickupBorough:string,
DropoffBorough:string
) [
"https://raw.githubusercontent.com/mwaskom/seaborn-data/master/taxis.csv"
] with(format='csv', ignoreFirstRecord=true);
TaxiData
| where isnotempty(PickupBorough)
| where PickupBorough == DropoffBorough
Suppose (for the sake of an example) that we’re interested in statistics for journeys within a single borough, that start and end in ‘frequently used’ zones (so, we’ll filter out unpopular zones).
Here is the distribution of journeys by PickupZone and DropoffZone:
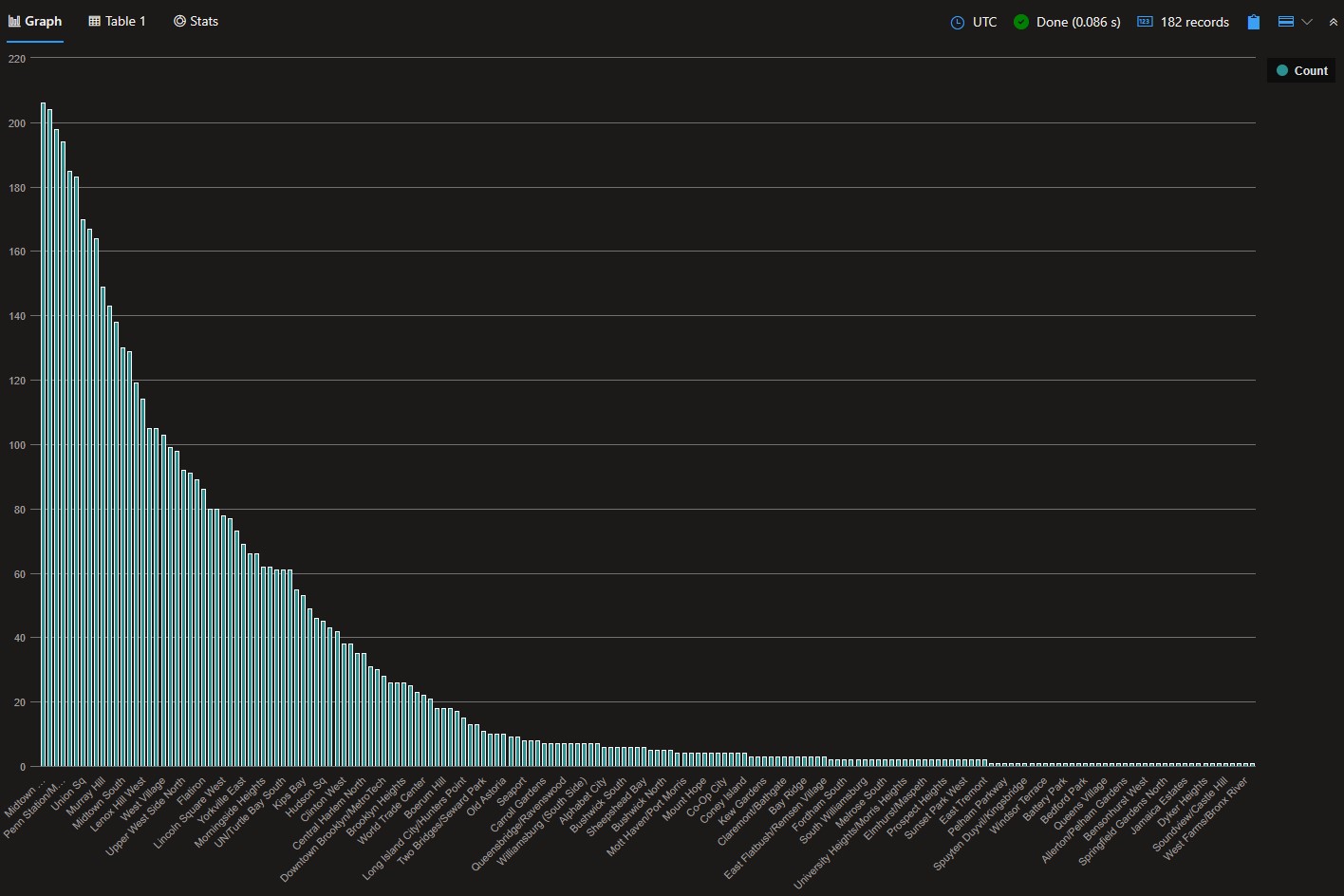
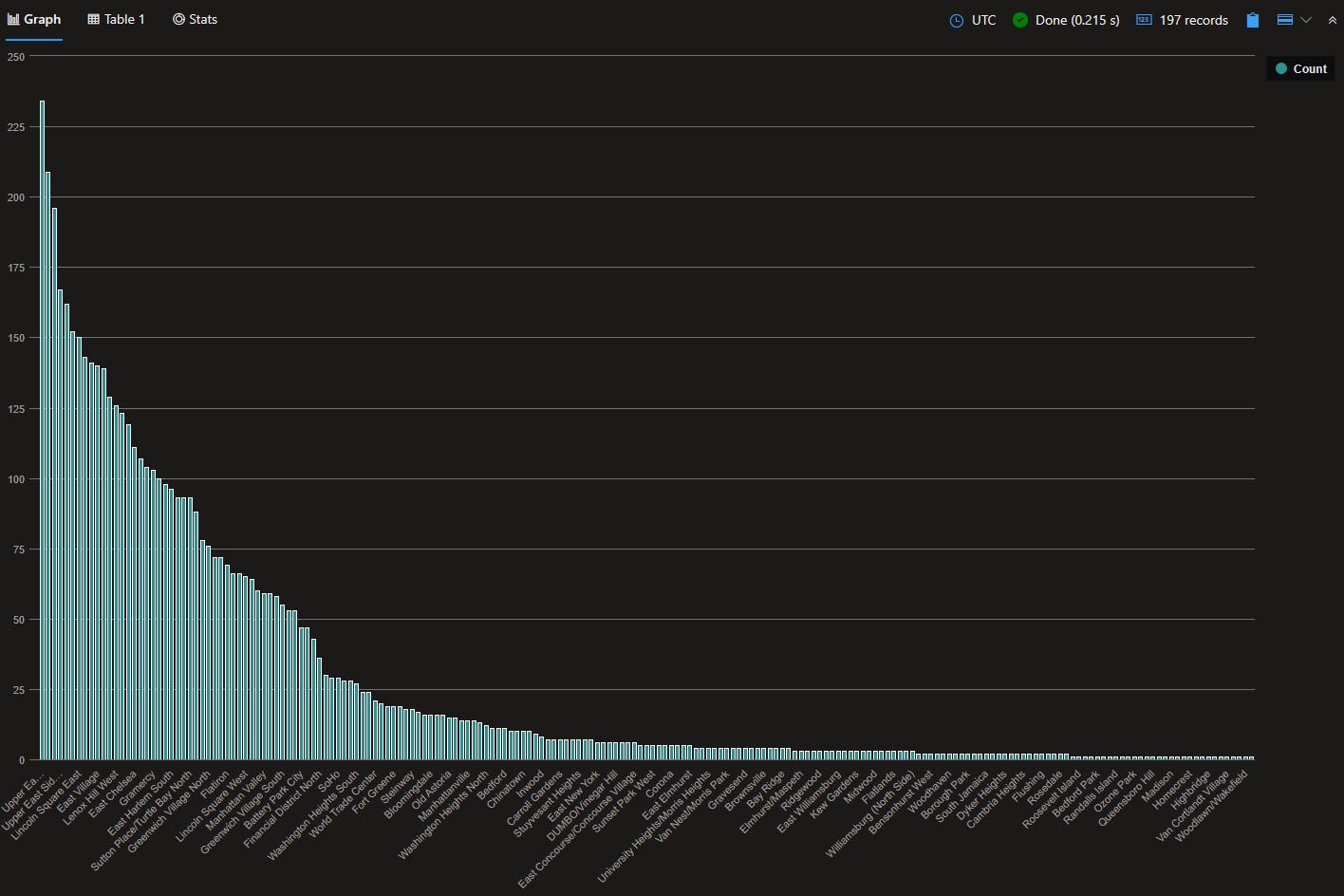
So, ~20 feels like a good threshold to use.
Summarisation
The KQL summarize operator is the best way to generate summary statistics for rows of data. So, we can do something like the following:
TaxiData
| where isnotempty(PickupBorough)
| where PickupBorough == DropoffBorough
| summarize Count = count() by PickupZone
| where Count >= 20
| order by Count desc
Which gives us our set of PickupZones with >= 20 journeys:
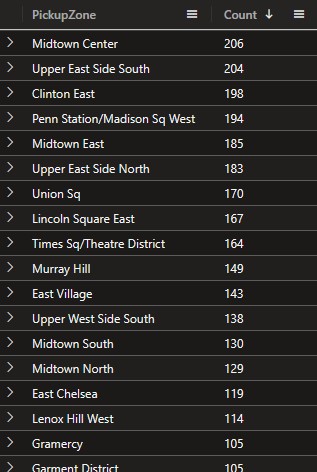
However, because we’ve summarised, we’ve lost the original data!
Self-Join
This is where self-join is particularly useful - we can summarize within an inner join clause to select the original rows that meet our summarisation
criteria - but without losing the original rows.
Typically, the query will proceed as follows:
- Get some large set of rows and pre-filter these. Save these pre-filtered rows with a
let X = .... inner joinXagainst itself, based on somesummarize ...criteria to select interesting rows.
Simple Self-Join
A basic self-join will look like:
X
| join kind=inner (
X
| summarize Count = count() by Y
| where Count >= 10
) on Y
This will give us all rows in X that have a value for Y where that Y appears in >= 10 rows.
Taxi Self-Join
So, as an example for our Taxi data, we can do something like the following:
let TaxiData = externaldata(
Pickup:datetime,
Dropoff:datetime,
Passengers:int,
Distance:real,
Fare:real,
Tip:real,
Tolls:real,
Total:real,
Color:string,
Payment:string,
PickupZone:string,
DropoffZone:string,
PickupBorough:string,
DropoffBorough:string
) [
"https://raw.githubusercontent.com/mwaskom/seaborn-data/master/taxis.csv"
] with(format='csv', ignoreFirstRecord=true);
let SameBoroughTaxiData = TaxiData
| where isnotempty(PickupBorough)
| where PickupBorough == DropoffBorough;
SameBoroughTaxiData
// Select rows that pickup from a common zone
| join kind=inner (
SameBoroughTaxiData
| summarize PickupZoneJourneyCount = count() by PickupZone
| where PickupZoneJourneyCount >= 20
) on PickupZone
| project-away PickupZone1
// Select rows that dropoff to a common zone
| join kind=inner (
SameBoroughTaxiData
| summarize DropoffZoneJourneyCount = count() by DropoffZone
| where DropoffZoneJourneyCount >= 20
) on DropoffZone
| project-away DropoffZone1
// Continue analysis ...
Which gives us a table of individual journey rows, where the journey is within the same borough, and where the start and end zones are frequently used. We can now continue our analysis to produce interesting stats based on just these rows.
Interesting analysis left as an exercise for the reader…
Additional Notes
- Rather than
let X = ..., an alternative is to use the| asoperator to capture an intermediate table state. materialize()or| as hint.materialized=truewill come in useful for large or complex datasets.leftsemiorleftantiare also interesting join types that are often useful with this pattern.